Probability distribution
In probability theory and statistics, a probability distribution identifies either the probability of each value of a random variable (when the variable is discrete), or the probability of the value falling within a particular interval (when the variable is continuous).[1] The probability distribution describes the range of possible values that a random variable can attain and the probability that the value of the random variable is within any (measurable) subset of that range.

When the random variable takes values in the set of real numbers, the probability distribution is completely described by the cumulative distribution function, whose value at each real x is the probability that the random variable is smaller than or equal to x.
The concept of the probability distribution and the random variables which they describe underlies the mathematical discipline of probability theory, and the science of statistics. There is spread or variability in almost any value that can be measured in a population (e.g. height of people, durability of a metal, sales growth, traffic flow, etc.); almost all measurements are made with some intrinsic error; in physics many processes are described probabilistically, from the kinetic properties of gases to the quantum mechanical description of fundamental particles. For these and many other reasons, simple numbers are often inadequate for describing a quantity, while probability distributions are often more appropriate.
There are various probability distributions that show up in various different applications. One of the more important ones is the normal distribution, which is also known as the Gaussian distribution or the bell curve and approximates many different naturally occurring distributions. The toss of a fair coin yields another familiar distribution, where the possible values are heads or tails, each with probability 1/2.
Contents |
Formal definition
In the measure-theoretic formalization of probability theory, a random variable is defined as a measurable function X from a probability space 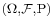 to measurable space
to measurable space 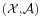 . A probability distribution is the pushforward measure X*P = PX −1 on .
. A probability distribution is the pushforward measure X*P = PX −1 on .
Probability distributions of real-valued random variables
Because a probability distribution Pr on the real line is determined by the probability of a real-valued random variable X being in a half-open interval (-∞, x], the probability distribution is completely characterized by its cumulative distribution function:
![F(x) = \Pr \left[ X \le x \right] \qquad \forall x \in \mathbb{R}.](/2010-wikipedia_en_wp1-0.8_orig_2010-12/I/6e5ecb80a21894d0b63c8b60156258da.png)
Discrete probability distribution
A probability distribution is called discrete if its cumulative distribution function only increases in jumps. More precisely, a probability distribution is discrete if there is a finite or countable set whose probability is 1.
For many familiar discrete distributions, the set of possible values is topologically discrete in the sense that all its points are isolated points. But, there are discrete distributions for which this countable set is dense on the real line.
Discrete distributions are characterized by a probability mass function,  such that
such that
![\Pr \left[X = x \right] = p(x).](/2010-wikipedia_en_wp1-0.8_orig_2010-12/I/d124a35cf09eac55a869e9c1bfa23e18.png)
Continuous probability distribution
By one convention, a probability distribution 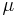 is called continuous if its cumulative distribution function
is called continuous if its cumulative distribution function ![F(x)=\mu(-\infty,x]](/2010-wikipedia_en_wp1-0.8_orig_2010-12/I/8d1ffb980813a124537f761f082a05d5.png) is continuous and, therefore, the probability measure of singletons
is continuous and, therefore, the probability measure of singletons 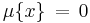 for all
for all 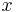 .
.
Another convention reserves the term continuous probability distribution for absolutely continuous distributions. These distributions can be characterized by a probability density function: a non-negative Lebesgue integrable function 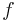 defined on the real numbers such that
defined on the real numbers such that
![F(x) = \mu(-\infty,x] = \int_{-\infty}^x f(t)\,dt.](/2010-wikipedia_en_wp1-0.8_orig_2010-12/I/41882dedea3ba5430b8267370c175c4d.png)
Discrete distributions and some continuous distributions (like the Cantor distribution) do not admit such a density.
Terminology
The support of a distribution is the smallest closed interval/set whose complement has probability zero. It may be understood as the points or elements that are actual members of the distribution.
A discrete random variable is a random variable whose probability distribution is discrete. Similarly, a continuous random variable is a random variable whose probability distribution is continuous.
Simulated sampling
The following algorithm lets one sample from a probability distribution (either discrete or continuous). This algorithm assumes that one has access to the inverse of the cumulative distribution (easy to calculate with a discrete distribution, can be approximated for continuous distributions) and a computational primitive called "random()" which returns an arbitrary-precision floating-point-value in the range of [0,1).
define function sampleFrom(cdfInverse (type="function")):
// input:
// cdfInverse(x) - the inverse of the CDF of the probability distribution
// example: if distribution is [[Gaussian]], one can use a [[Taylor approximation]] of the inverse of [[erf]](x)
// example: if distribution is discrete, see explanation below pseudocode
// output:
// type="real number" - a value sampled from the probability distribution represented by cdfInverse
r = random()
while(r == 0): (make sure r is not equal to 0; discontinuity possible)
r = random()
return cdfInverse(r)
For discrete distributions, the function cdfInverse (inverse of cumulative distribution function) can be calculated from samples as follows: for each element in the sample range (discrete values along the x-axis), calculating the total samples before it. Normalize this new discrete distribution. This new discrete distribution is the CDF, and can be turned into an object which acts like a function: calling cdfInverse(query) returns the smallest x-value such that the CDF is greater than or equal to the query.
define function dataToCdfInverse(discreteDistribution (type="dictionary"))
// input:
// discreteDistribution - a mapping from possible values to frequencies/probabilities
// example: {0 -> 1-p, 1 -> p} would be a [[Bernoulli distribution]] with chance=p
// example: setting p=0.5 in the above example, this is a [[fair coin]] where P(X=1)->"heads" and P(X=0)->"tails"
// output:
// type="function" - a function that represents (CDF^-1)(x)
define function cdfInverse(x):
integral = 0
go through mapping (key->value) in sorted order, adding value to integral...
stop when integral > x (or integral >= x, doesn't matter)
return last key we added
return cdfInverse
Note that often, mathematics environments and computer algebra systems will have some way to represent probability distributions and sample from them. This functionality might even have been developed in third-party libraries. Such packages greatly facilitate such sampling, most likely have optimizations for common distributions, and are likely to be more elegant than the above bare-bones solution.
Some properties
- The probability density function of the sum of two independent random variables is the convolution of each of their density functions.
- The probability density function of the difference of two independent random variables is the cross-correlation of their density functions.
- Probability distributions are not a vector space – they are not closed under linear combinations, as these do not preserve non-negativity or total integral 1 – but they are closed under convex combination, thus forming a convex subset of the space of functions (or measures).
List of probability distributions
See also
|
|
|
Notes
- ↑ Everitt, B.S. (2006) The Cambridge Dictionary of Statistics, Third Edition. pp. 313–314. Cambridge University Press, Cambridge. ISBN 0521690277
External links
- An 8 foot tall Probability Machine (named Sir Francis) comparing stock market returns to the randomness of the beans dropping through the quincunx pattern. from Index Funds Advisors IFA.com, youtube.com
- Interactive Discrete and Continuous Probability Distributions, socr.ucla.edu
- A Compendium of Common Probability Distributions
- A Compendium of Distributions, vosesoftware.com
- Statistical Distributions - Overview, xycoon.com
- Probability Distributions in Quant Equation Archive, sitmo.com
- A Probability Distribution Calculator, covariable.com
- Sourceforge.net, Distribution Explorer: a mixed C++ and C# Windows application that allows you to explore the properties of 20+ statistical distributions, and calculate CDF, PDF & quantiles. Written using open-source C++ from the Boost.org Math Toolkit library.
- Explore different probability distributions and fit your own dataset online - interactive tool, xjtek.com
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||

|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||